Accuracy is the single most important question in synthetic audience research. If the outputs do not reflect how real people think and behave, the technology has no value. At Electric Twin, we take this question seriously and seek to make our accuracy measures as clear and easily understood as possible. Therefore, we measure our accuracy using two complementary statistical methods - one the industry standard, the second more rigorous that we believe better defines how well it works in the real world.
This article explains how we validate our synthetic audiences, and what the results tell you about the reliability of our platform.

What Electric Twin Does
Electric Twin creates synthetic audiences using large language models combined with real survey data. We construct detailed synthetic personas based on demographic and contextual information using first and third party datasets. Each persona functions as an agent capable of responding to questions in ways that mirror real individuals from target populations. We then query these synthetic personas to generate predictions about how real-world populations would respond to various scenarios.
This allows the platform to construct any audience that an organisation might want to represent from its data, from understanding USA Gen Z’s interaction in the attention economy, to how the UK public think about banking needs.
The practical question is simple: when Electric Twin predicts a distribution of responses, how close is that prediction to reality?
How We Test Accuracy
Our validation methodology uses strict data separation to prevent any form of data leakage.
We split each dataset into two parts. The first part, persona creation data, provides demographic and contextual information used to build synthetic personas. The second part, evaluation data, is completely held out during persona creation and used solely for testing predictions.
Evaluation questions are never included in persona creation. This ensures that our synthetic personas generate responses based on their characteristics, not memorised answers.
All the data used in the evaluation is private data that is not available on the internet ensuring that the underlying models are not simply reproducing results in their training data.
We then ask our synthetic audiences the same held-out questions and compare the predicted distribution directly against the real-world population answers. This is the same principle used across science: train on one set of data, test on another.
Two Ways to Measure Accuracy: 1-MAE and NDAM
There are different ways to measure how close a predicted distribution is to a real one. We report two metrics because each tells a different part of the story.
1-MAE (One Minus Mean Absolute Error)
1-MAE is the industry-standard accuracy measure for comparing predicted and actual survey distributions. It calculates the average absolute difference between predicted and actual response proportions, then subtracts that error from 1 to produce an accuracy score.
Electric Twin achieves 95.5% accuracy on 1-MAE.
This metric is widely used and easy to understand. It works well for comparing systems on a like-for-like basis. However, it has a limitation: it becomes more lenient as the number of answer options increases.
Here is why. On a two-option question (e.g. yes/no), 1-MAE can range from 0% to 100%. If you are completely wrong, you score 0%. That makes sense. But on a three-option question, the worst possible score is 33%, not 0%. The more answer options a question has, the higher the floor. This means 1-MAE can flatter performance on questions with many response categories.
For a commercial headline number, 1-MAE is useful. For scientific rigour, we need something stricter.
NDAM (Normalised Distribution Accuracy Measure)
NDAM solves the limitation of 1-MAE. It normalises the accuracy score so that it always ranges from 0 to 1, regardless of how many answer options a question has. A score of 0 means completely wrong. A score of 1 means a perfect match. This makes NDAM a fairer, more demanding ruler.
Electric Twin achieves 92% accuracy on NDAM.
Because NDAM penalises errors more heavily, scores are naturally lower than 1-MAE. This does not mean the system is less accurate. It means the measurement is stricter. From our interviews with end users, we believe NDAM better represents the ruler of what ‘good’ looks like.
To put 92% NDAM in context: when you ask the same survey question twice to the same group of real people, the agreement between their two sets of answers sits at approximately 94% NDAM. This is the natural ceiling created by human response variability. Electric Twin’s 92% NDAM score sits within 2 percentage points of this human noise level.
Why Use Both Metrics?
Electric Twin achieves 95.5% accuracy on 1-MAE. As it is widely used, it allows for comparison, however this metric can be lenient for questions with many answer options.
Internally we evaluate our engine against the stricter standard: NDAM. Under this more rigorous measure, Electric Twin still achieves 92% accuracy. Reporting both numbers gives you the full picture: a commercially recognisable headline and a scientifically rigorous score that gives you a clearer perspective.
To compare the strictness of these metrics below is the accuracy of the same predictions over our white paper validation set, measured on both scales.
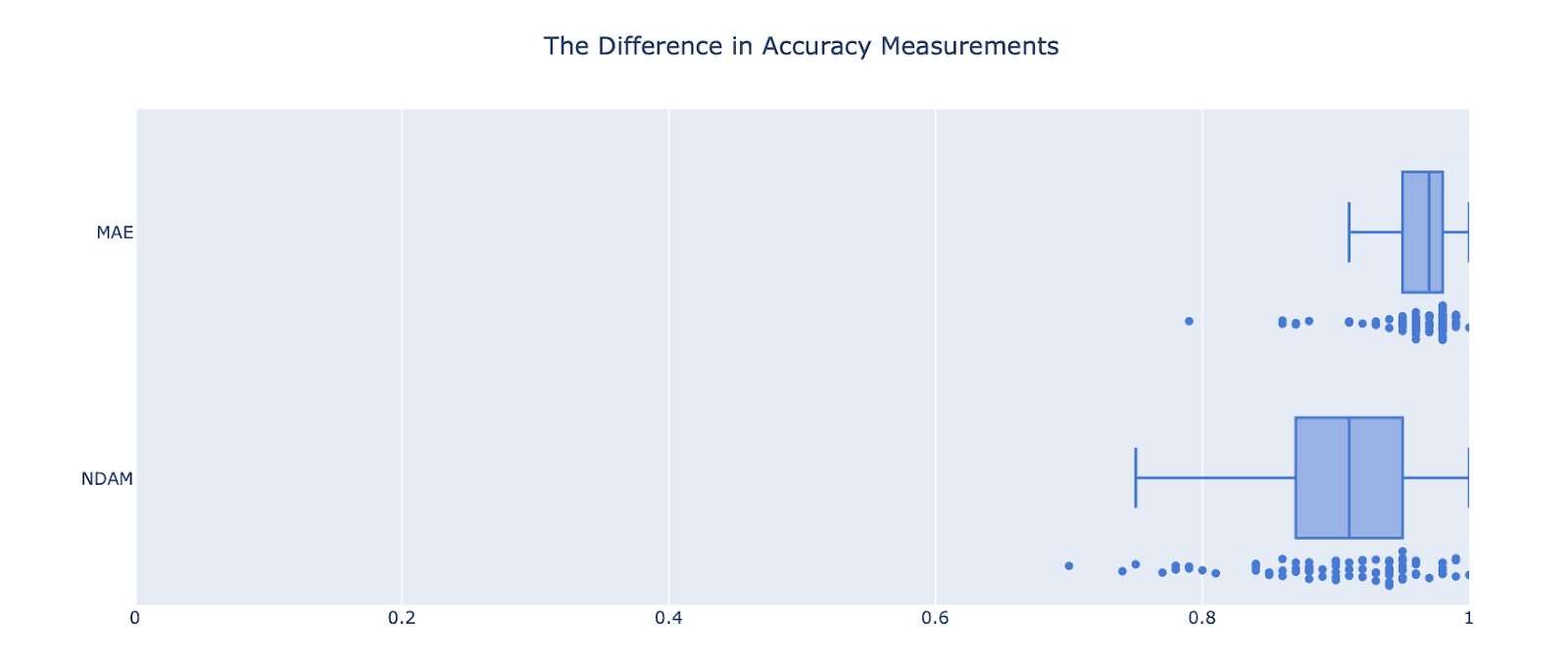
How We Compare to Traditional Research
We ran eight traditional survey methods, including opt-in panels, river sampling, and platforms like Prolific and MTurk, when we compare each against a baseline of the average of all we see an accuracy of 96% 1-MAE.
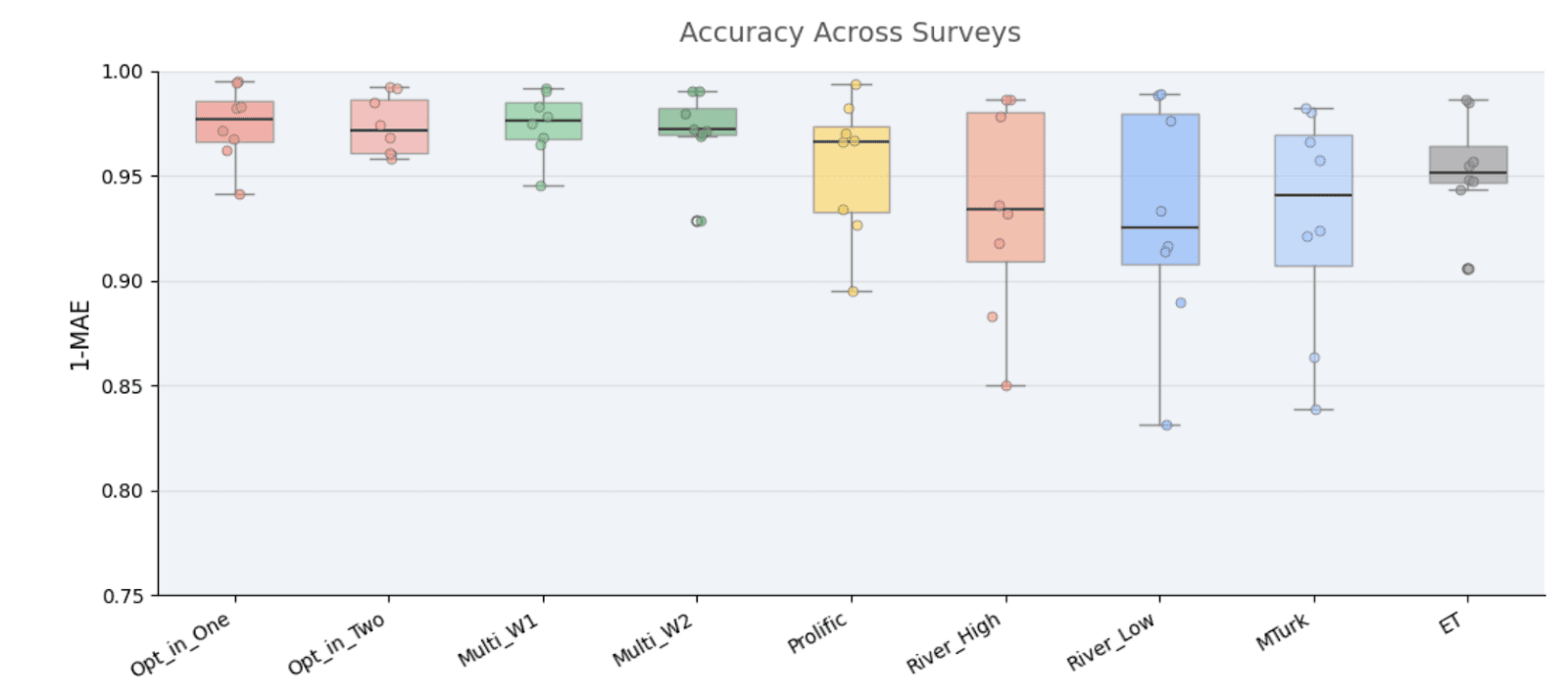
Electric Twin sits at 95.5% against the same baseline of the average of other techniques.
The individual methods within traditional research show a range. Opt-in panels score as high as 97.5% (noting that they make up the majority of techniques pulling the average towards them). Prolific achieves around 96.0%. River sampling sits between 93% and 94%. MTurk comes in at 93%. Electric Twin’s accuracy is comparable to the average across these established methods.
On the stricter NDAM measure, the “same question twice” benchmark (asking the same group the same question in two separate survey waves) produces approximately 94% accuracy. Electric Twin’s 92% NDAM sits close to this natural variability threshold. The remaining gap reflects the inherent noise in any survey-based measurement, not a systematic flaw in synthetic prediction.
Continuous Improvement
We run accuracy evaluations continuously, not as a one-off validation exercise. Our accuracy has improved consistently since June 2024, and our current scores represent our latest model performance.
Three factors drive these improvements.
First, we have refined how we construct personas, identifying which information is most predictive and excluding noise.
Second, we have improved our post-processing methods, including how we convert model outputs into probability distributions.
Third, the underlying large language models we access through APIs have themselves improved over time.
We track accuracy across every question and every dataset. This means we can identify where our predictions are strongest and where specific question types present challenges, feeding that insight back into our development cycle.
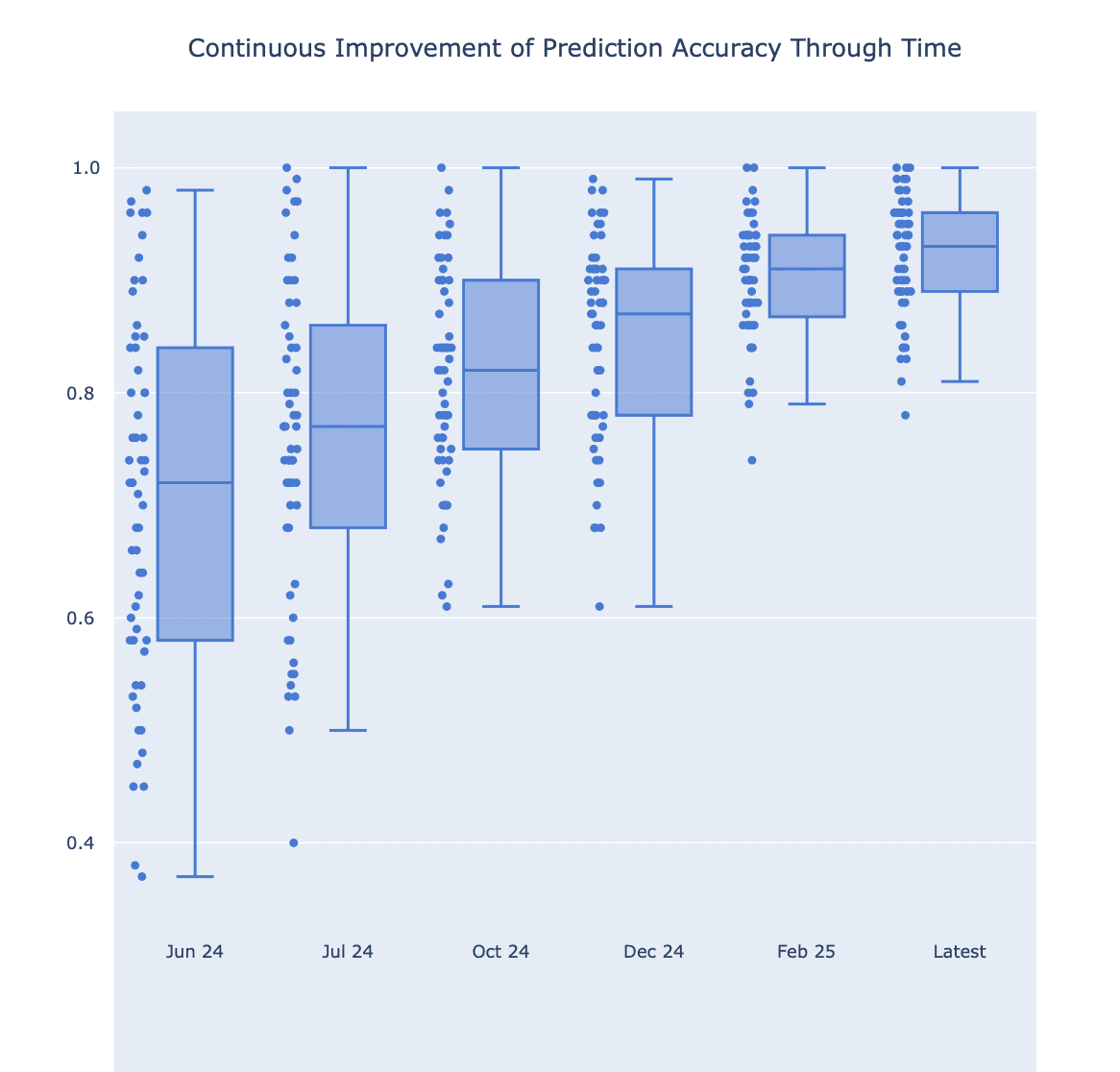
What 92% NDAM Means in Practice
When Electric Twin predicts that 35% of a population will select a particular answer, the actual figure from a real survey will typically fall within a few percentage points of that prediction. Across hundreds of questions and thousands of personas, this level of consistency holds.
For organisations making decisions based on audience understanding, this accuracy level provides a reliable foundation. Traditional research carries its own margin of error. Surveys are themselves approximations of reality, shaped by sampling method, question wording, and respondent engagement. Electric Twin’s synthetic predictions sit within the same range of accuracy as these established methods, while delivering results in seconds rather than weeks.
Frequently Asked Questions
How does Electric Twin prevent data leakage in accuracy testing? We use strict dataset partitioning. Evaluation questions are completely held out during persona creation. Synthetic personas never see the test questions during construction, so their responses reflect genuine prediction, not memorisation.
What is the difference between NDAM and 1-MAE? Both measure how close a predicted distribution is to the actual distribution. 1-MAE is the industry standard and produces higher scores. NDAM is stricter because it normalises the score to always range from 0 to 1, regardless of the number of answer options. We report both for transparency.
How accurate is Electric Twin compared to traditional surveys? On 1-MAE, Electric Twin scores 95.5% compared to an average of approximately 96% across traditional research methods. On NDAM, Electric Twin scores 92% compared to a human noise level of approximately 94% (the agreement when the same question is asked twice).
How many personas does Electric Twin use? Our accuracy evaluations are based on 11,000 unique personas spanning UK and US populations.
Is Electric Twin’s accuracy improving over time? Yes. We have improved by an average of 20% on NDAM since launch, driven by better persona construction, improved post-processing, and underlying model improvements. We evaluate accuracy continuously, not as a one-off exercise.
Authors:
Dr Ben Warner, Co-Founder
Andrew Bailey, Research Engineer